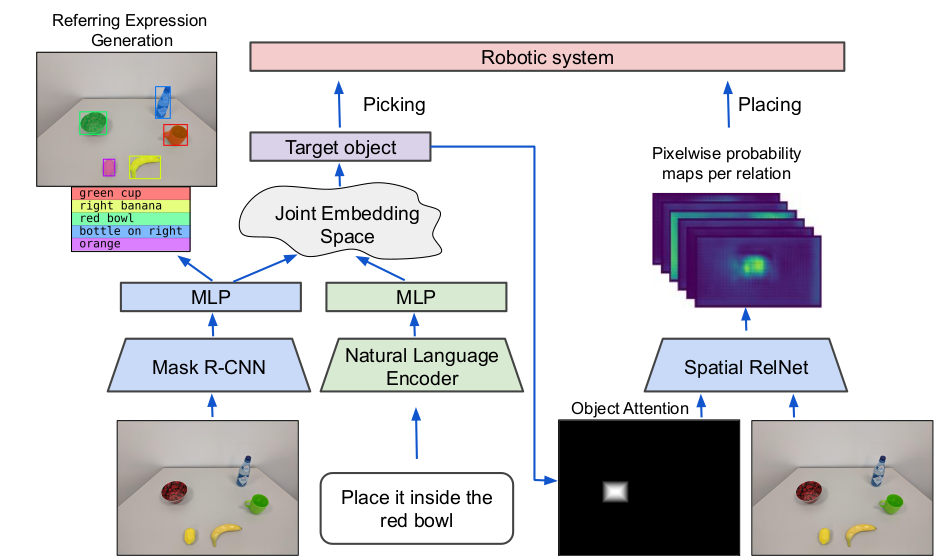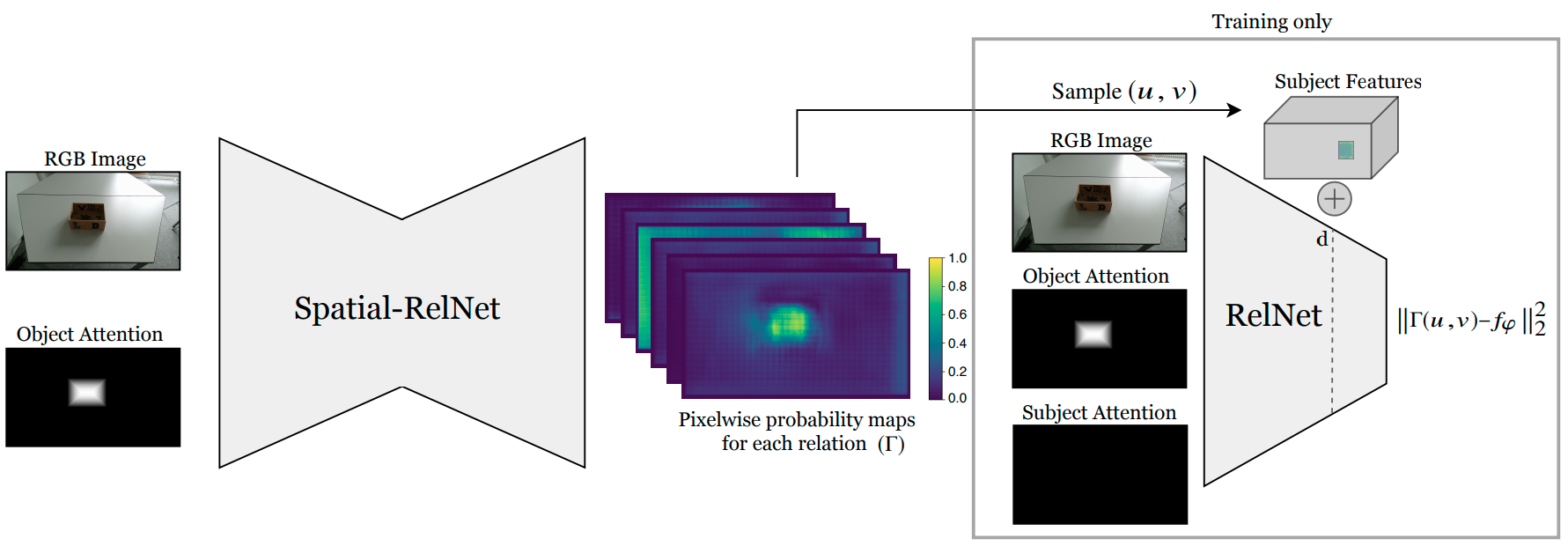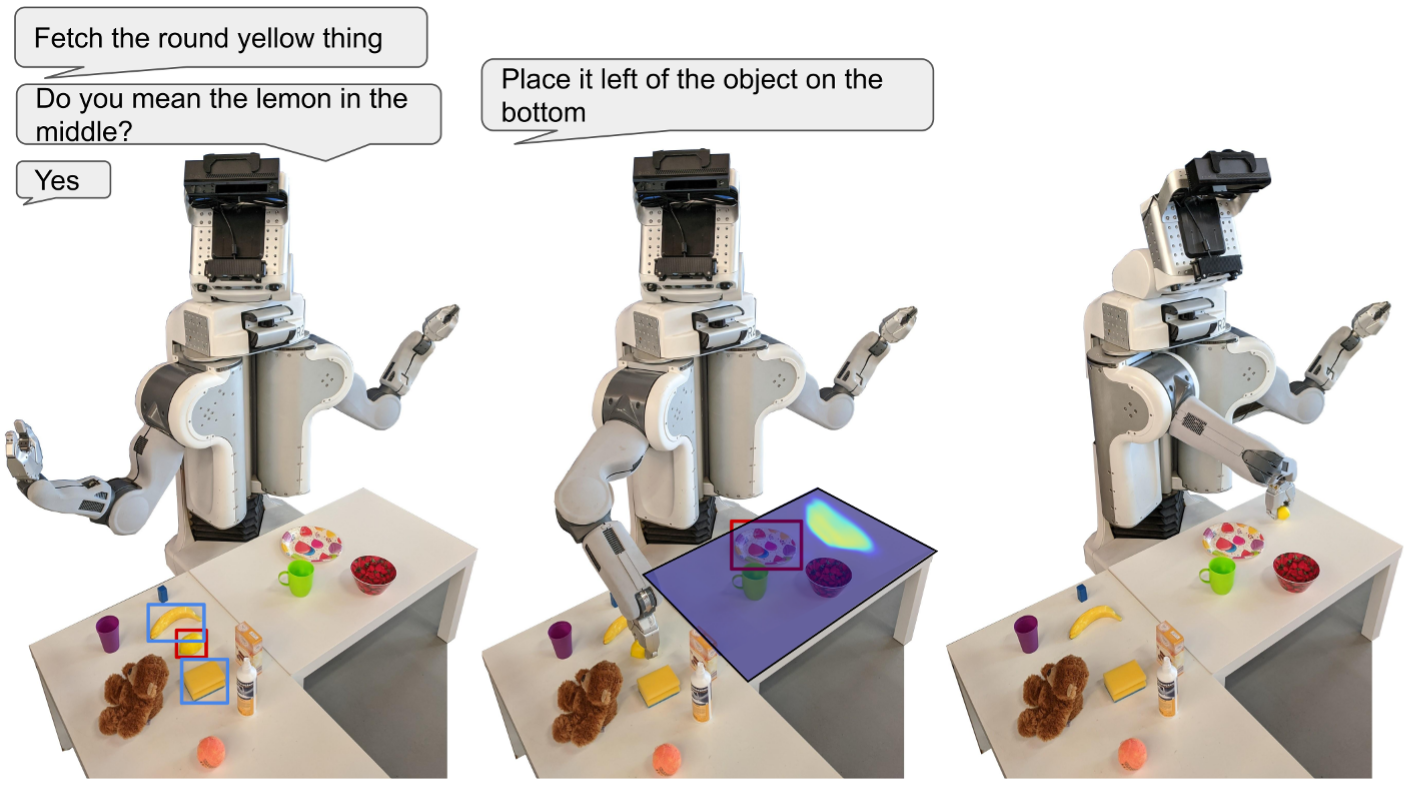
Controlling robots to perform tasks via natural language is one of the most challenging topics in human-robot interaction. In this work, we present a robot system that follows unconstrained language instructions to pick and place arbitrary objects and effectively resolves ambiguities through dialogues. Our approach infers objects and their relationships from input images and language expressions and can place objects in accordance with the spatial relations expressed by the user. Unlike previous approaches, we consider grounding not only for the picking but also for the placement of everyday objects from language.
Specifically, by grounding objects and their spatial relations, we allow specification of complex placement instructions, e.g. "place it behind the middle red bowl". Our results obtained using a real-world PR2 robot demonstrate the effectiveness of our method in understanding pick-and-place language instructions and sequentially composing them to solve tabletop manipulation tasks.